Introduction and context:
Attention has really performed well across a lot of NLP tasks. Though it was introduced as a complimentary approach along with Sequential models(RNNs, LSTMs), now attention is solely giving state of art performances for all type of NLP models. All the recent Language Models are based on Transformers architecture and attention is the most important building block of it.
Even the recent models developed by OpenAI such as GPT-3 uses transformer. The use of RNNs has been diluted with the rise of attention. I am going to discuss attention specifically self-attention and it's use around HANs(Hierarchical Attention Networks)
What is attention and why is it needed:
To understand why attention is necessary, let's look at the RNN architectures which were the state-of-art deep learning models for NLP.
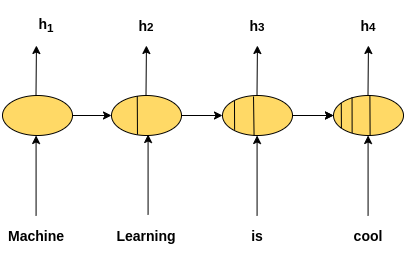 Fig. 1: Vanilla Recurrent Neural Network.
Fig. 1: Vanilla Recurrent Neural Network.
The problem with this is information flows sequentially and for longer sequences the context is limited to the neighbouring elements or time steps. LSTMs does a decent job to handle long sentences with the introduction of an extra cell, but LSTMs are also not ideal for longer sequences. Let's say I am building a movie review classification model. It would be great if I can focus on all elements of the input instead of just the last hidden state. One way can be to sum or pool all the hidden states in some way and send that to a layer to do the classification. But it would be more ideal if I can pool or sum the hidden states in a weighted manner(giving appropriate weight or attention) to the hidden states. That's exactly what attention does(this is one type of attention though). So how can you take a weighted sum of all the hidden states.
Learning to Attend
Let's consider an example from a real dataset:
"The acting here is good but the film fails in cinematography,screenplay,directing and editing"
We can say that the overall sentiment of the sentence is negative. The most important part of sentences are probably "acting here is good" and "but the film fails". Attention does a great job at finding this pattern. It can decide which part of the sequence is important through the weights. Let's consider a more simpler example to understand the use of attention.
"The acting here is good"
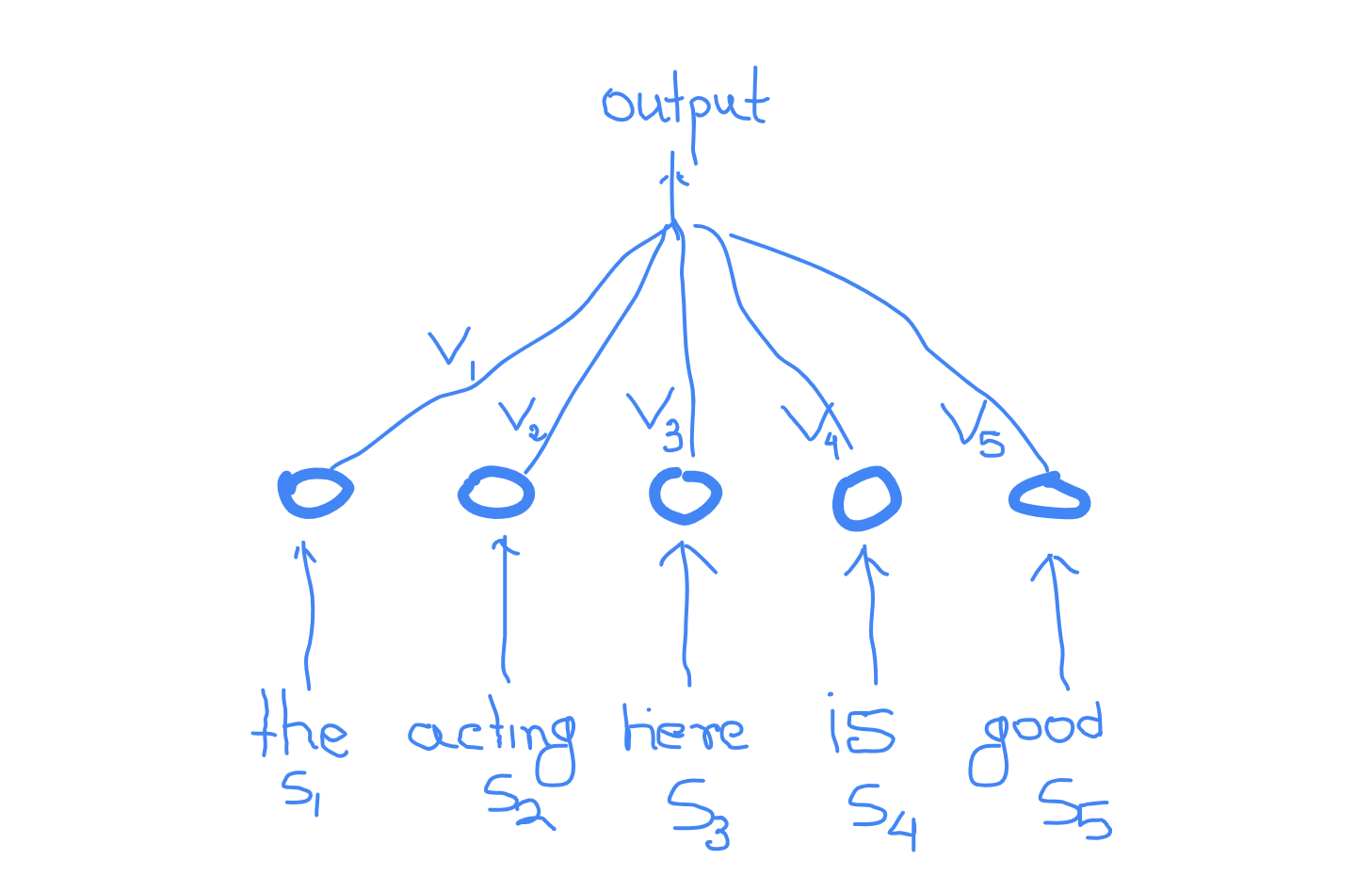
Fig. 2: Learning to attend features
It's clear 'good' is the key part for predicting sentiment here. Now, we can imagine 5 different numbers ${v_{1},v_{2},v_{3},v_{4},v_{5}}$ deciding which word gets how much weight or attention. In this case $v_{5}$ should be greater than any of the other. Now we can just make these attention weights learnable, but there are some obvious problems with that. First, the weights needs to be dependent on the input and second, we can't really have different learnable weights for each position as our sentences will be variable length(and of course we don't want our weights to be position dependent). So, we can reasonibly compose the attention wegits as the following:
\begin{equation} v_{i} = function(s_{i}) \end{equation} We are halfway there. Now, the most common transformation or function we can put here is linear transformation followed by a nonlinear one(like relu, tanh).
\begin{equation} v_{i} = Relu(W_{attention}s_{i}+b_{attention}) \end{equation} Here $v_{i}$ denotes how much attention you are paying to the ith input while deriving the output. This isn't the usual attention mechanism used. But I started with this to make things clear. Of course the functions and input to the function will be more complex depending on the type use cases, but the basic idea remains the same. Note: In the above case, $v_{i}$ is supposed to be a scalar. In the above example, attention has been used to rank the input sequence. We will see a scenario where the features gets to interact with each other and create a new set of features. This is will be more closer to actual attention mechanism used.
In Machine Translation attention:
The first mention of attention I have seen was in the NEURAL MACHINE TRANSLATION paper. They tried to solve the problem of capturing temporal relationship without being limited by the distance between two related events.
Machine translation is a seq2seq model consisting of an encoder and a decoder. For a english-french translation, the encoder encodes the english input sentence and the decoder predicts the sentence in french in step-by-step fashion.
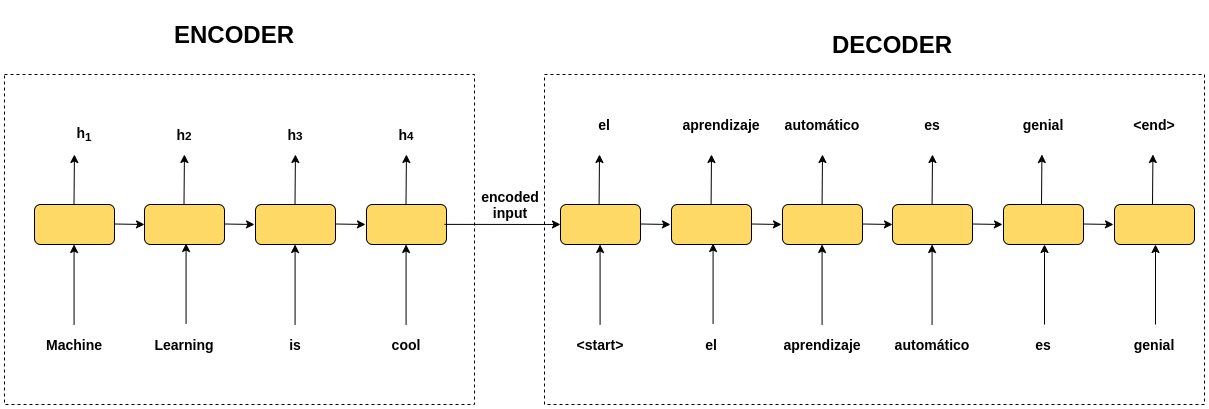 Fig. 3: Seq2Seq architecture for english to spanish machine translation
Fig. 3: Seq2Seq architecture for english to spanish machine translation
Problem with traditional Seq2Seq
The problem with this architecture is that all the inputs are encoded into a single vectors making it difficult to remember inputs at the beginning. Another problem here is that the alignment of words may not be the same in different languages. Both of this requires a direct involvement of the inputs with the outputs. Attention does exactly that.
The NEURAL MACHINE TRANSLATION paper proposes a alignment model to take care of this issue. The idea is to use a context vector c derived from the encoder hidden states.
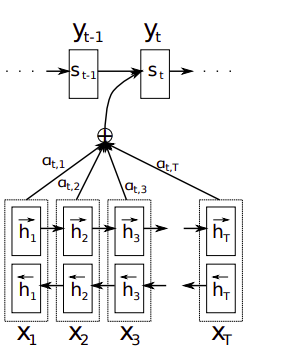
Fig. 4: Attention in Neural machine translation
This figure is directly from the paper. $(h_{1}, h_{2}, h_{3}… h_{T})$ are used to calculate the context vector $c_{i}$
While predicting the ith output from the decoder, one more input(the context vector) is used than a traditional seq2seq decoder.
Context vector: The context vector is calculated as a weighted summation of encoder hidden state vectors.
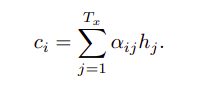
The weights for summing hidden state vector are calculated in a similar manner as Fig 2
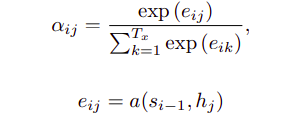
Where a is a alignment model which calculates the weight for jth encoder hidden state while calculating ith decoder prediction step. Of course the the weights are normalized by a softmax. a is often just a feed forward neural network.
In case of self-attention a is a function of only the input vectors(the vectors taking the weighted sum). So, in case of self-attention the a function would become something like this:
\begin{equation}
e_{ij} = a(h_{i}, h_{j})
\end{equation}
I tried to make use of self-attention for a dataset and listed down few key observations about self-attention.
Experiment Setup:
I have worked on a sentiment classification from problem to test my hypotheses around attention.
Dataset
The dataset is for binary sentiment classification. Each review consist of multiple sentences making this a hierarchical task(work on a sentence first and the combine the sentences). Total 25000 train dataset is available along with 25000 test dataset. Link to dataset: link
Our network will have a hierarchical structure. One sequential model encodes words of a single sentence into sentence vectors while the other sequential model encodes these sentence vectors into a paragraph vector which is then used for a binary classification. And of course, we will use self-attention in both the networks.
Sample Data:
From the beginning of the movie, it gives the feeling the director is trying to portray something, what I mean to say that instead of the story dictating the style in which the movie should be made, he has gone in the opposite way, he had a type of move that he wanted to make, and wrote a story to suite it. And he has failed in it very badly. I guess he was trying to make a stylish movie. Any way I think this movie is a total waste of time and effort. In the credit of the director, he knows the media that he is working with, what I am trying to say is I have seen worst movies than this. Here at least the director knows to maintain the continuity in the movie. And the actors also have given a decent performance.
Model:
There are two Sequential Model. First one encodes a sentence using a LSTM and additive attention and the second one encodes sequence of sentences to encode a document.
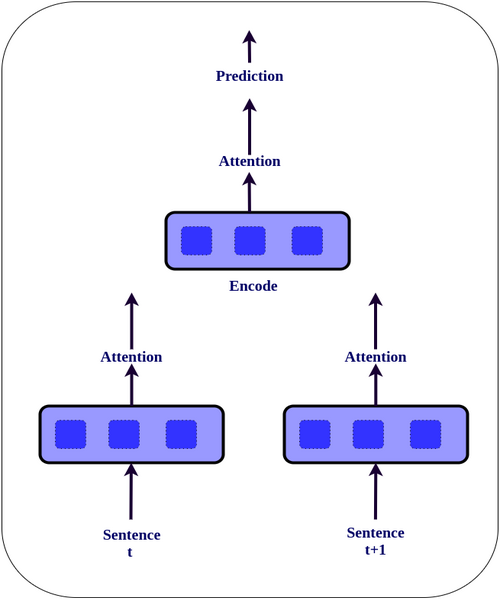
Fig. 4: Hierarchical Attention Networks for Document Classification
The figure shows the hierarchical attention networks for two sentence input. We can easily extend this for more sentences as well. We can see how attention learns to rank the sentences for impacting the review sentiment using the attention weights.
Let's take this example:
The Underground Comedy Movie, is possibly the worst train wrecks I've ever seen. Luckily I didn't pay for this movie, and my friend reluctantly agreed to watch it again siting that it was so awful but he needed to prove to me how awful it was. I love off color comedy. I figured at the least it would have that and I would be entertained. No, instead the acting was so awful, the “jokes” were extremely cheesy, and the plot was no where to be found. Maybe there wasn't supposed to be a plot so I can't hold that against this movie. It's pretty sad where the funniest thing in a comedy is an old woman having her head hit off by a bat…..by Batman…A man dressed in a baseball uniform wielding a bat. Hilarious. Simply genius. I got the feeling watching this movie that its creators made it and laughed hysterically with their friends about it. Perhaps this was full of inside jokes we just didn't understand. Or perhaps it's the worst piece of trash ever made and it should be locked away in a vault and dumped in the Arctic Ocean. P.S. Don't buy this movie!
The most important sentence for this(sentence with most attention weight):
Or perhaps it's the worst piece of trash ever made and it should be locked away in a vault and dumped in the Arctic Ocean.
Which kind of makes sense.
Observation:
Attention weights has a dimension of (t_steps, tsteps) where t_step is the number of words in the sentence. Normally, (i,j) element of the matrix provides how much interaction there is between ith and jth words irrespective of their distance. In general you can also take any row and the t_steps sized vector will produce the ranking of words.
It is also observed that all the rows of attention weight matrix are almost same in case sentence attention vectors. The attention weights in case of sentences are more useful for ranking. This is expected as it is very difficult to interact different sentences as more or less they provide independent information.
In case of Word attention, the attention weights vary across the rows(not a lot). This provides a sense that the attention weights not only create ranking but also measures the level of interactions between words to create more useful features.
Note: All experiments were performed in Google Colab(Awesome free GPU support) and CPU from e2e networks